
( …continues from previous week. )
Welcome to the Perl review pages for Week 146 of The Weekly Challenge! Here we will take the time to discuss the submissions offered up by the team, factor out some common methodologies that came up in those solutions, and highlight some of the unique approaches and unusual code created.
●︎ Why do we do these challenges?
I suppose any reasonable answer to that question would be from a field as wide ranging and varied as the people who choose to join the team. One thing, though, is clear: it’s not a competition, and there are no judges, even if there is a “prize” of sorts. About that – I think of it more as an honorarium periodically awarded to acknowledge the efforts we make towards this strange goal. So there’s no determination to find the fastest, or the shortest, or even, in some abstract way, the best way to go about things, although I’m certain the participants have their own aspirations and personal drives. As Perl is such a wonderfully expressive language, this provides quite a bit of fodder to the core idea of TMTOWTDI, producing a gamut of varied techniques and solutions.
Even the tasks themselves are often open to a certain amount of discretionary interpretation. What we end up with is a situation where each participant is producing something in the manner they find the most interesting or satisfying. Some team members focus on carefully crafted complete applications, thoroughly vetting input data and handling every use case they can think up. Others choose to apply themselves to the logic of the underlying puzzle and making it work in the most elegant way they can. Some eschew modules they would ordinarily reach for, others embrace them, bringing to light wheels perhaps invented years ago that happen to exactly solve the problem in front of them today.
I’ve been considering this question for some time and have found one binding commonality between all of us out solving these challenges each week, in that however we normally live our lives, the task in front of us more than likely has nothing to do with any of that. And I think this has great value. We all do what we do, in the real world, and hopefully we do it well. The Weekly Challenge provides us with an opportunity to do something germane to that life yet distinctly different; if we only do the things we already know how to do then we will only do the same things over and over. This is where the “challenge” aspect comes into play.
So we can consider The Weekly Challenge as providing a problem space outside of our comfort zone, as far out from that comfort as we wish to take things. From those reaches we can gather and learn things, pick and choose and bring what we want back into our lives. Personally, I think that’s what this whole thing is about. YMMV.
Every week there is an enormous global collective effort made by the team, analyzing and creatively coding the submissions, and that effort deserves credit due.
And that’s why I’m here, to try and figure out ways to do that.
So, here we are then — let’s ge to it and see what we can find.
For Additional Context…
Before we begin, you may wish to revisit either the pages for the original tasks or the summary recap of the challenge. But don’t worry about it, the challenge text will be repeated and presented as we progress from task to task.
Oh, and one more thing before we get started:
Getting in Touch with Us
 Email › Please feel free to email me (Colin) with any feedback, notes, clarifications or whatnot about this review.
Email › Please feel free to email me (Colin) with any feedback, notes, clarifications or whatnot about this review.
 GitHub › Submit a pull request to us for any issues you may find with this page.
GitHub › Submit a pull request to us for any issues you may find with this page.
 Twitter › Join the discussion on Twitter!
Twitter › Join the discussion on Twitter!
I’m always curious as to what the people think of these efforts. Everyone here at the PWC would like to hear any feedback you’d like to give.
• Task 1 • Task 2 • BLOGS •
TASK 1
10001st Prime Number
Submitted by: Mohammad S Anwar
Write a script to generate the 10001st prime number.
about the solutions
Abigail, Adam Russell, Andrezgz, Arne Sommer, Athanasius, Bruce Gray, Colin Crain, Dave Jacoby, Duncan C. White, E. Choroba, Flavio Poletti, Ian Goodnight, Jaldhar H. Vyas, James Smith, Jorg Sommrey, Laurent Rosenfeld, Matthew Neleigh, Mohammad S Anwar, Niels van Dijke, Pete Houston, Peter Campbell Smith, Robert DiCicco, Roger Bell_West, Simon Green, Ulrich Rieke, and W. Luis Mochan
Sounds simple enough, right? There are no instructions on how to go about producing this value, only to do so. The first task is, by unwritten convention, the easier of the two offerings, and so should be able to be solvable by beginner and expert alike, perhaps paralleled in matching easy and complex manners. A good task should be scalable you might say, with regards to how much effort a member is able to expend.
For whatever reasons, really. We’re not here to micromanage. You do you, as they say.
I’ve noticed people here, when given an easy out, don’t usually take it. Considering participation in the challenges are purely voluntary to begin with — we could save all the time by not playing at all — the answers end up a function of whatever level, or angle, a member has been working on lately. Different folks have different priorities, and different amounts of free time.
That said, no one actually submitted say 104743, although some threatened to.
However that would have worked, of course. It is the right answer.
There were 26 submissions for the first task this past week.
A SELECTION of SUBMISSIONS
James Smith, Jorg Sommrey, Laurent Rosenfeld, Mohammad S Anwar, Roger Bell_West, Flavio Poletti, Ian Goodnight, Colin Crain, Athanasius, Andrezgz, and Robert DiCicco
If we ever needed the value of the 10,001th prime, specifically, for some unfathomable reason, we’d surely just look it up if we wanted to include it in a script. If we were being conscientious to good form we might abstract it from the logic by saying
use constant { P-TEN-THOUSAND-ONE => 104743 };
or similar. One thing we would be extremely unlikely to do would be to derive it. But, you know, in order for us to be able to look it up in a reference work now someone had to do the work then, for some value of then.
So, of course, we’re going to do just that. Or, you know, something.
I feel a far more likely use-case would be to need some large prime numbers, perhaps identified by index, that were large enough that their values were not commonly known. In these cases, then, “ten-thousand” becomes shorthand for “some arbitrarily big number”. This is appropriate terminology, as the phrase is often used in this context. When a stressed-out individual says “I have ten-thousand things to do today!” they are not likely to mean that literally. And Lao Tzu writes of “the ten-thousand things” in the Tao Te Ching to mean the whole of everything. Some innumerable quantity. Or put another way, some arbitrarily big number.
At this point, after having done many challenges involving prime numbers, experienced team members will already have a go-to method for acquiring primes, either as lists or iterators supplying the next in the sequence. Consequently we saw a variety of means to either make primes outright or fetch them on demand from some black-box that delivers.
additional languages: Python, Raku, Swift
Well start the show with Mohammad, who offers up a pair of routines: one that checks a value for primeness and a wrapper function that tries out and delivers a specific quantity of successful candidates.
To check primality, we try possible factors from 2 to the square root of the candidate. Any factor greater than the square root will have a compliment factor less than it as well, so searching up to that point will cover all possibilities.
To create a list of primes we start counting up and adding the next one found until we’ve gathered enough.
sub find_prime {
my ($count) = @_;
my $c = 0;
my $n = 2;
while ($c <= $count) {
if (is_prime($n)) {
return $n if (++$c == $count);
}
$n++;
}
}
sub is_prime {
my ($n) = @_;
foreach my $i (2 .. sqrt $n) {
return 0 unless $n % $i
}
return 1;
}
additional languages: Julia, Raku, Ring
blog writeup: Perl Weekly Challenge 146: Prime Numbers and Fraction Tree
Laurent starts his long list of primes with the first three values, and then counts by twos from there, only considering odd numbers for candidates. A second optimization he brings in to prune the search space is to only use the growing list of primes as possible factors. We don’t, after all, need to know specifically whether 4 is a factor; it will suffice to know that 2 is a factor first and stop there. We continue to divide against the list of primes until we exceed the square root, and if we get that far the candidate has passed the test and is added to the prime list, to be considered from that point as a factor for later candidates down the line.
use constant MAX => 10_001;
sub primes {
my $max = shift;
my @primes = (2, 3, 5);
my $count = 3;
my $candidate = $primes[-1];
while ($count <= $max) {
$candidate += 2;
my $not_prime = 0;
my $sq_cand = sqrt $candidate;
for my $i (@primes) {
$not_prime = 1, last unless $candidate % $i;
last if $i > $sq_cand;
}
next if $not_prime;
push @primes, $candidate;
$count ++;
}
return $primes[$max-1];
}
my $p = primes(MAX);
say "$p";
blog writeup: Perl Weekly Challenge #146
James adds the interesting choice in optimizing to avoid the square root operator, instead squaring each prime to see whether the product is larger than the candidate. This practically serves the same purpose — that we stop when a possible factor’s multiplicative complement will have already been checked — but makes the trade-off of swapping many small simple calculations for one big complex one.
I have no inside information how the exchange fares in the end, but I do trust James to have done the homework for us, as that is kind of his thing.
He has also, again as is his wont, made it crushingly compact. As in: “getting all hydraulic-press” on it.
my($c,@p)=(5,3);
for(;@p<10000;$c+=2){
($_*$_>$c)?((push@p,$c),last):$c%$_||last for@p;
}
say$p[-1];
He offers an expanded version on his blog writeup, for the confused and abused among us:
my @primes = (3);
my $c = 3;
while( @primes < 10000 ) {
$c += 2;
foreach ( @primes ) {
if( $_*$_ > $c ) {
push @primes, $c;
last;
}
unless( $c % $_ ) {
last;
}
}
}
say $primes[-1];
That’s definitely going to be easier to follow, by anybody’s reckoning.
To complete our stylistic introduction to the field of submissions we will jump now to Jorg, who demonstrates a good plan should we ever require the use of a variety of arbitrarily-yet-specifically selected large primes in a real project.
This is of course is to let some highly-tuned piece of code perform the calculations for us. The number-theory toolkit Math::Prime::Util has a routine that will deliver us the n-th prime on demand. There are 53 functions directly pertaining to processing prime numbers in Math::Prime::Util, and that’s not counting factoring, semiprimes or pseudoprimes. This one is aptly named nth_prime().
perl -MMath::Prime::Util=:all -E 'say nth_prime(10001)'
Math::Prime::Util, a.k.a. ntheory, provides a treasure trove of functions for all things prime. You want anything to do with primes around here, well, as they say in New York: “Hold on, I gotta guy.”
additional languages: Javascript, Kotlin, Lua, Postscript, Python, Raku, Ruby, Rust
blog writeup: RogerBW’s Blog: The Weekly Challenge 146: Curious Prime
There’s more that one way to build a list of primes. A popular option in approaching the problem is instead of adding newly proven values with a lot of testing, we remove values that are easily proven to be not prime.
This works well. We start with a known field of sequential candidates (starting from 2), and we pick the lowest number and cross out multiples of it: times 2; times 3; times 4; et cetera until we reach our upper bound. We then pick the next number that hasn’t been crossed out and remove all multiples for that one. In each pass we leave the originals alone, and when we are done we have a list of primes.
There’s one more part of the trick, in that we only need to start with numbers up to the square root of the maximum; a convenient way to present this graphically is to arrange the field itself in a square:
# 2 3 4 5 # 2 3 # 5 <-- we only need to work the top row
6 7 8 9 10 # 7 # # #
11 12 13 14 15 ---> 11 # 13 # #
16 17 18 19 20 # 17 # 19 #
21 22 23 24 25 # # 23 # #
Neat, right? The only problem (that you might have picked up on already) is that to know when to stop searching we need an upper bound, whether we take the square root mathematically or graphically. And that’s a problem, because although using this method it’s easy to find, say, the primes under 10,000, we have no easy way to know how many numbers we need to sieve to produce 10,000 primes.
Roger gets around this by establishing some boundaries, which is always a healthy thing to do. In this case we cannot know exactly how many numbers to process, but we can apply an inequality attributed to Barkley Rosser:
Pn < n log (n log n) : n ≥ 6
to know when we will have more than enough. This says the n-th prime will be less than the formula value for indices over 6, until… at least some ridiculously large number. It’s not exactly proven, but is proven within the range we’re looking into.
To well beyond the number of protons in the universe. So we’re pretty well covered there.
The method is known as the Sieve of Eratosthenes, and Roger’s version implements a variety of optimizations worthy of a look, so I’ll include the whole thing:
sub nthprime {
my $n=shift;
my $m=15;
if ($n >= 6) {
$m=int(1+$n*log($n*log($n)));
}
my $primes=genprimes($m);
return $primes->[$n-1];
}
sub genprimes {
my $mx=shift;
my @primes;
{
my %primesh=map {$_ => 1} (2,3);
for (my $i=6;$i <= $mx; $i += 6) {
foreach my $j ($i-1,$i+1) {
if ($j <= $mx) {
$primesh{$j}=1;
}
}
}
my @q=(2,3,5,7);
my $p=shift @q;
my $mr=int(sqrt($mx));
while ($p <= $mr) {
if ($primesh{$p}) {
my $i=$p*$p;
while ($i <= $mx) {
delete $primesh{$i};
$i += $p;
}
}
if (scalar @q < 2) {
push @q,$q[-1]+4;
push @q,$q[-1]+2;
}
$p=shift @q;
}
@primes=sort {$a <=> $b} keys %primesh;
}
return \@primes;
}
additional languages: Raku
blog writeup: PWC146 - 10001st Prime Number - ETOOBUSY
I want to start out with an assertion to Flavio that I have, at this time, nothing whatsoever to do with the selection and framing of the tasks here at TWC. I’ve often thought to offer, but frankly I have way too much on my plate already. On the other hand I’m blushing to think he’s ascribe such diabolical motives to me as to purposely want to trip people up by requesting the ten-thousand-and-FIRST prime, versus, say, the ten-thousandth or some other simple, round index.
That does sound like me, I have to say.
Then again I have noticed I’ve been seemingly kinder and more forgiving lately. Selecting fewer reviews at random has allowed me the option to pretend some scripts simply don’t exist. I don’t enjoy dwelling on failure. I think of my role here as to boost people up, you know? It’s a happy job, right? Right?
Right? (Looks around, sees only turtles. The fish is asleep.)
The dark side only pops up in the humor, which I have no idea whether anyone even gets.
Ah, well. Such is life.
Flavio’s primal hunt involves keeping both a list of primes and a second, parallel list of squares of those values. After priming the pump (the hits just keep on coming, don’t they?) he selects a candidate as the last prime gathered plus two. Then he tries dividing against the accumulating prime list using an incremental index until the square exceeds the candidate, by using the index on the parallel list. On failing out and finding a divisor he adds two to the candidate and tries again. Maintaining the second list is a pretty clever way to avoid computing the squares of the primes more than once. I like it.
sub prime_at ($n) {
state $primes = [ undef, 2, 3 ];
state $squares = [ undef, 4, 9 ];
FIND_NEW:
while ($primes->$#* < $n) {
my $candidate = $primes->[-1] + 2;
while ('necessary') {
for my $i (2 .. $primes->$#*) {
if ($squares->[$i] > $candidate) {
push $primes->@*, $candidate;
push $squares->@*, $candidate * $candidate;
next FIND_NEW;
}
last unless $candidate % $primes->[$i];
}
$candidate += 2;
}
}
return $primes->[$n];
}
additional languages: Javascript, Python, Ruby
I had to venture out of my editor to properly regard Ian’s efforts, because he includes some fancy formatting, adding ANSI escape codes to jazz things up. A little color is always nice to brighten up your day. I approve.
Unwilling or unable to stop there, Ian goes on to include a small routine to form a proper ordinal construction for the requested value: 10,001 goes to 10001st for “first”. Again, a nice touch, interfacing to the humans in the manner to which they are accustomed.
The rules here, like everything in Natural Language Programming, have evolved over centuries in a steady, continuous fashion. The linguistic necessity has has never slaked, and the notion of correctness always descriptive; people have always had to speak in quantities and there is no discreet break where Old English speakers suddenly became cosmopolitan Middle English sophisticates.
So it’s a bit of a thicket, to say the least, geting this right. I might suggest a superseding rule on the tens’ place, that if there is a 1 there, the suffix becomes “th” no matter the contents of the ones, as in “three-hundred and eleventh”. That’s the only one I can think of offhand; there may be others. Thicket, I say.
I admit I kind of love that stuff. I almost tripped-up above writing out “ten-thousand and first”. It’s such a mess. It must drive the more literal-minded programmers mad.
sub get_suffix {
my $last_digit = substr shift, -1;
if ( $last_digit == 0 || $last_digit >= 4 ) {
return 'th';
}
if ( $last_digit == 1 ) {
return 'st';
}
if ( $last_digit == 2 ) {
return 'nd';
}
if ( $last_digit == 3 ) {
return 'rd';
}
return q{ };
}
sub color_string {
my $str = shift;
my $color = shift;
my %colors = (
yellow => "\e[33m",
green => "\e[32m",
);
my $reset = "\e[0m";
return $colors{$color} . $str . $reset;
}
################################################################################
# Main #########################################################################
################################################################################
my $nth = shift @ARGV // '10001';
my $prime = get_prime $nth;
my $suffix = get_suffix $nth;
my $num_string = color_string( $nth . $suffix, 'yellow' );
my $prime_string = color_string( $prime, 'green' );
print "The $num_string prime number is $prime_string\n";
additional languages: Raku
For my own solution I offer up my prime generator, by this point tightly crafted and refined. The early assignment sets the candidate to 1 and the prime list to the single element 2, and the stacked conditions of the while loop immediately increment the candidate to 3 and we’re off and running. I take the square root once per candidate and store it to avoid repeating this relatively expensive operation.
sub make_primes_quantity ( $quantity ) {
## creates a list of the first $quantity primes
my ($candidate, @primes) = ( 1, 2 );
CANDIDATE: while ( $candidate += 2 and @primes < $quantity ) {
my $sqrt_candidate = sqrt( $candidate );
for my $test ( @primes ) {
next CANDIDATE if $candidate % $test == 0;
last if $test > $sqrt_candidate;
}
push @primes, $candidate;
}
return \@primes;
}
additional languages: Raku
The monk, like Roger, uses a sieve for their prime filtration, and so is also required to grapple with the problem of determining how large a pool they need to sift through. Using a different inequality from J. Barkley Rosser this time1, we determine a lower bound with
n/log n < Pn
which sets the required sieve size to 116,700. This is externally calculated and included along with the target index as constants. I note Rosser’s name seems to pop up a lot around primes. Good for him.
The sieve itself is a straightforward study. Of note, with a nod over to Ian, I’ll also include the monk’s commify() routine for inserting commas into the output numbers according to convention, so we write “10,001” properly. The ordinal suffix, on the other hand, is wired in.
Since we seem to be on the subject, I’ll make a sensible suggestion to all who care about such things to have a look at Neil Bowers’ excellent module Lingua::EN::Numbers, designed to facilitate properly creating ordinal numbers, and additionally Damian Conway’s Lingua::EN::Inflexion which may well find use in following up, to get the various tenses right. These two are gold.
const my $TARGET => 10_001;
const my $SIEVE_SZ => 116_700; # See discussion above
my $count = 0;
my @sieve = (0) x $SIEVE_SZ;
my $latest_prime;
for my $i (2 .. $#sieve)
{
if ($sieve[ $i ] == 0)
{
$latest_prime = $i;
last if ++$count >= $TARGET;
for (my $j = $i * $i; $j <= $#sieve; $j += $i)
{
$sieve[ $j ] = 1;
}
}
}
printf "The %sst prime number is %s\n",
commify( $count ), commify( $latest_prime );
#------------------------------------------------------------------------------
# Adapted from: https://perldoc.perl.org/perlfaq5#
# How-can-I-output-my-numbers-with-commas-added%3F
#
sub commify
#------------------------------------------------------------------------------
{
my ($n) = @_;
1 while $n =~ s/ ^ ([-+]? \d+) (\d{3}) /$1,$2/x;
return $n;
}
1 Rosser, J. Barkley; Schoenfeld, Lowell (1962). “Approximate formulas for some functions of prime numbers”. Illinois J. Math. 6: 64–94.
Premature optimization is, in the real world, a cardinal sin. So if the programs here finish in realistic — for some definitions of realistic — spans of time, well, then who are we to say what’s right and wrong?
Ok, I mean, I am, I suppose, if they don’t actually produce the correct results. But let’s not nit-pick.
Andrezgz looks at successive values and tries dividing them out by everything up to the square root until he finds enough of them. End of story. The result is 104743.
I like the condensed style. The primes aren’t gathered, only counted. When the count is right the cascading conditional is finally allowed to complete and the current prime is printed. It’s elegant in its stripped-down simplicity.
do {} until (is_prime(++$n) && ++$count == 10001 && print $n);
sub is_prime {
my $n = shift;
#every composite number has a prime factor less than or equal to its square root.
return 1 == grep {$n % $_ == 0} (1 .. sqrt $n);
}
We’ll close with Robert, who uses a similar logical flow: to keep getting the next prime until we have counted enough. However this time we draw again on the venerable ntheory, a synonym for Math::Prime::Util, which among its myriad options contains a function next_prime(). Given a prime it returns the next one. Would you look at that.
use ntheory qw/ next_prime /;
### AUTHOR: Robert DiCicco
### DATE: 04-JAN-2022
### Challenge #145 10001st Prime
my $cnt = 0;
my $i = 1;
my $TARGET = 10001;
while($cnt <= $TARGET){
if($cnt == $TARGET ){
last;
}
$cnt++;
$i = next_prime($i);
}
print("Count = $cnt : prime = $i\n");
Blogs and Additional Submissions in Guest Languages for Task 1:
additional languages: Awk, Bash, Basic, Bc, Befunge-93, C, Cobol, Csh, Erlang, Forth, Fortran, Go, Java, Lua, M4, Mmix, Node, Ocaml, Pascal, Php, Postscript, Python, R, Rexx, Ruby, Scheme, Sed, Sql, Tcl
blog writeup: Perl Weekly Challenge 146: 10001st Prime Number
blog writeup: Sieve of Atkin / Curious Fraction Tree — RabbitFarm
additional languages: Raku
blog writeup: Fractionally Prime with Raku and Perl
additional languages: Raku
blog writeup: TWC 146: 10K Prime and CW Trees
blog writeup: Fractions, Trees and Primes: Weekly Challenge 146 | Committed to Memory
additional languages: Raku
blog writeup: Perl Weekly Challenge: Week 146
blog writeup: Large primes and curious fractions
additional languages: Python
blog writeup: 2 Fractions and a Prime
additional languages: C++, Haskell, Raku
blog writeup: Perl Weekly Challenge 146 – W. Luis Mochán
TASK 2
Curious Fraction Tree
Submitted by: Mohammad S Anwar
Consider the following Curious Fraction Tree:
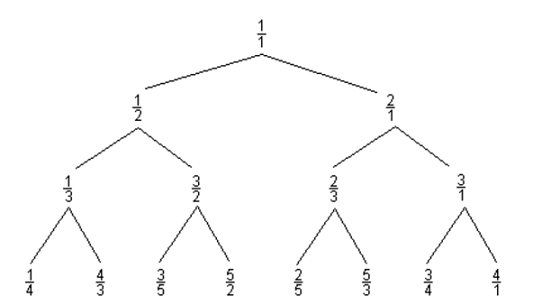
You are given a fraction, member of the tree created similar to the above sample.
Write a script to find out the parent and grandparent of the given member.
Example 1:
Input: $member = '3/5';
Output: parent = '3/2' and grandparent = '1/2'
Example 2:
Input: $member = '4/3';
Output: parent = '1/3' and grandparent = '1/2'
about the solutions
Abigail, Adam Russell, Andrezgz, Arne Sommer, Athanasius, Bruce Gray, Colin Crain, Dave Jacoby, Duncan C. White, E. Choroba, Flavio Poletti, Ian Goodnight, Jaldhar H. Vyas, James Smith, Laurent Rosenfeld, Matthew Neleigh, Niels van Dijke, Pete Houston, Peter Campbell Smith, Robert DiCicco, Roger Bell_West, Simon Green, Ulrich Rieke, and W. Luis Mochan
What, may I ask, is this “Curious Fraction Tree”?
I like this challenge, as it presents, in high relief, the fundimental differences members take in approaching these problems — and how these conceptual differences correspond in turn to the relationship these challenges have to the real world.
As a programmer, one is often exposed to novel confluences of known data and required results, forming puzzles that need to be solved to proceed. This is in fact the very stuff of programming, that we are continually beset with problems that both resemble yet are importantly differentiated from situations we’ve dealt with before. Just the other day I wanted to sort numerically — sure, done that — but sort according to numbers grabbed in a regex. Oh, that’s weird and unusual and doesn’t just work.
So the correct form here is to use the second invaluable programming skill and research the solution. Don’t reinvent the wheel. You may not need to do this often but somebody probably does, so use your time efectively and learn from them. I ended up with a variant on a Schwartzian transform, named after legendary Perl guru Randal Schwartz. I didn’t make up that method myself, Randall did, although the final product I installed it in is my own unique assemblage of bits and pieces I’ve learned along the way. That part — the big picture part — that’s mine.
There’s a direct analogy to the human condition sitting right there, you know.
On the other hand I like puzzles, and personally do these challenges to solve puzzles. And part of a really good puzzle is figuring out what the puzzle is. As a programmer the sensible thing would be to google some keywords and find the solution. Researching is a skill that requires honing same as any other so I cannot and will not deride this strategy.
-
So I looked at the data and figured out what was happening and its properties.
-
Others seemingly recognized it as a Calkin-Wilf tree and went from there.
-
Still others googled the term “Curious Fraction Tree” and researched the puzzle, versus the tree.
Thus depending on the scope of one’s initial focus — The numbers, the tree, or the puzzle about the tree — we find at least three equally-valid ideas on how to proceed. I find this meta-analysis in problem-solving fascinating. As the real-world is invariably messy and poorly-defined, this sort of thing pops up all the time.
There were 24 submissions for the second task this past week.
WHEELS within WHEELS, JUMPING through HOOPS
Dave Jacoby, Simon Green, Arne Sommer, Abigail, Peter Campbell Smith, E. Choroba, Adam Russell, Matthew Neleigh, and Bruce Gray
As previously mentioned, there were a number of fundamental positions taken in approaching this problem. Largely though, however they started, members ultimately landed in the fact that given a child node a set of procedural rules could be determined to produce a parent, and these rules could then be applied again recursively to find the parents of the parents, as far up the tree as desired. This became the essence of a generalized solution. For a specific solution involving just one tree, they built the tree as described.
blog writeup: Fractions, Trees and Primes: Weekly Challenge 146 | Committed to Memory
For Dave, he says he saw the task, saw the tree, and his respones was to build the tree and take it from there. This sounds like a perfectly reasonable reading of the requirements. So he whipped out a tree-building Node class and made sure it had a parent() method. Then he constructs the tree as written.
There is ambiguity from the word “similar” is the description. Are we talking about this specific tree as written, or a generalized tree that follows the same rules of construction? He chooses the former interpretation.
Once the tree is populated, he can traverse the entire structure and query every node as to its genealogical makeup. Then for each node a report is made up listing the node, its parent, and its parent’s parent. As every node ends up reported on, we have an answer to every given fraction in this particular tree.
my %node;
for my $i (
qw{
1/1 1/2 2/1
1/3 3/2 2/3
3/1 1/4 4/3
3/5 5/2 2/5
5/3 3/4 4/1
}
)
{
$node{$i} = Node->new($i);
}
$node{'1/1'}->left( $node{'1/2'} ); # 1
$node{'1/1'}->right( $node{'2/1'} ); # 1
$node{'1/2'}->left( $node{'1/3'} ); # 2
$node{'1/2'}->right( $node{'3/2'} ); # 2
... snip
for my $n ( sort keys %node ) {
my $node = $node{$n};
my $parent = '';
my $grandparent = '';
if ( defined $node->parent ) {
$parent = $node->parent->value;
if ( defined $node->parent->parent ) {
$grandparent = $node->parent->parent->value;
}
}
say <<"END";
INPUT: \$member = "$n"
OUTPUT: parent = "$parent" and grandparent = "$grandparent"
END
}
package Node;
sub new ( $class, $value = 0 ) {
my $self = {};
$self->{value} = $value;
$self->{left} = undef;
$self->{right} = undef;
$self->{horizontal} = undef;
$self->{parent} = undef;
return bless $self, $class;
}
sub value ( $self, $value = undef ) {
if ( defined $value ) {
$self->{value} = $value;
}
else {
return $self->{value};
}
}
sub left ( $self, $node = undef ) {
if ( defined $node ) {
$self->{left} = $node;
$node->{parent} = $self;
}
else {
return $self->{left};
}
}
sub right ( $self, $node = undef ) {
if ( defined $node ) {
$self->{right} = $node;
$node->{parent} = $self;
}
else {
return $self->{right};
}
}
sub parent ($self ) {
return $self->{parent};
}
additional languages: Python
blog writeup: 2 Fractions and a Prime
Simon looked at the tree and said something like: “You know, what we need here are some fractions”. Perl, unlike some languages like Raku, does not have the notion of a fraction built-in. So he decided to go get one.
Enter Neil Bower’s Number::Fraction module, which provides, essentially, a rational number datatype, with numerator and denominator components. He then goes on to note that those same fractional component values can be directly manipulated to produce the parent fraction without really needing a fraction tree at all. He can just break up his Number::Fraction object into its num and den hash values and work on them directly. New numerator and demoninator values are calculated and the results used to create a new Number::Fraction.
A custom stringification routine f() is used to produce the final parent and grandparent fractions.
sub get_parent {
my $f = shift;
# 1/1 and -1/1 are orphened fractions.
return undef if not defined $f or abs($f) == 1;
# Deal with postive fractions for now
my $new_n = abs( $f->{num} );
my $new_d = $f->{den};
if ( $new_n > $new_d ) { # f > 1
$new_n = $new_n - $new_d;
}
else {
$new_d = $new_d - $new_n;
}
# Turn the fraction back to negative if needed
$new_n = 0 - $new_n if $f < 0;
return Number::Fraction->new( $new_n, $new_d );
}
additional languages: Raku
blog writeup: Fractionally Prime with Raku and Perl
The fractions, you could say here, are inconsequential. Which is to say the actual value expressed, although ultimately interesting, does not enter into the question of how to determine the numbers representing the parent.
What we have here as far as the problem is concerned is a two-digit ordered tuple at each node, and based on these values alone we can compute the surrounding node data.
Arne has figured out there are two cases: when the numerator is larger than the denominator, and vice-versa. If larger, the top, first value is changed to the numerator minus the denominator. Otherwise, the bottom, second value becomes the denominator minus the numerator.
sub parent ($fraction)
{
my ($numerator, $denominator) = split("/", $fraction);
return "0/0" if $numerator == 1 && $denominator == 1;
$numerator < $denominator
? return $numerator . "/" . ( $denominator - $numerator )
: return ($numerator - $denominator ) . "/" . $denominator;
}
additional languages: Awk, Bash, Bc, C, Go, Java, Lua, Node, Pascal, Python, R, Ruby, Scheme, Tcl
blog writeup: Perl Weekly Challenge 146: Curious Fraction Tree
Abigail hones this action down to a simple ternary switch with two outcomes, each operating directly on the two values.
while (<>) {
my ($a, $b) = /[0-9]+/g;
for (1, 2) {
$a < $b ? ($b -= $a) : ($a -= $b);
last unless $a && $b;
print "$a/$b ";
}
print "\n";
}
blog writeup: Large primes and curious fractions
By copying the altered fraction components into new variables instead of overwriting the original values, Peter is able to report the parent and grandparents in a verbose manner:
The parent of 13/20 is 13/7
The grandparent of 13/20 is 6/7
The parent of 1/2 is 1/1
The grandparent of 1/2 does not exist
sub parents {
my ($a, $b, $pa, $pb);
# as described above
($a, $b) = @_;
if ($a / $b < 1) { # a left child
$pa = $a;
$pb = $b - $a;
} else { # a right child
$pa = $a - $b;
$pb = $b;
}
# not a member if pa or pb calculates as 0 or if a == b and a != 1
return (-1, -1) if ($pa == 0 or $pb == 0 or ($pa == $pb and $pa != 1));
return ($pa, $pb);
}
Remarkably, Choroba is able to reduce the code footprint even further.
sub parent {
my ($x, $y) = @_;
return $x < $y ? ($x, $y - $x) : ($x - $y, $y)
}
sub grandparent {
return parent(parent(@_))
}
blog writeup: Sieve of Atkin / Curious Fraction Tree — RabbitFarm
Adam’s approach was to build the tree using the Graph module framework, and then call predecessors() on the node found.
It turns out building the tree in Graph requires a bit of effort, but as with all good models, once we have the tree in place querying it to a node’s parent, or the parent’s parent, is analogous to simply looking at a drawing. We simply ask the object.
sub initialize{
my($member) = @_;
my $graph = new Graph();
$graph->add_vertex(ROOT);
my @next = (ROOT);
my @changes = ([0, 1], [1, 0]);
my $level = 0;
{
my @temp_next;
my @temp_changes;
do{
$level++;
my $next = shift @next;
my($top, $bottom) = split(/\//, $next);
my $change_left = shift @changes;
my $change_right = shift @changes;
my $v_left = ($top + $change_left->[0]) . SEPARATOR . ($bottom + $change_left->[1]);
my $v_right = ($top + $change_right->[0]) . SEPARATOR . ($bottom + $change_right->[1]);
$graph->add_edge($next, $v_left);
$graph->add_edge($next, $v_right);
push @temp_next, $v_left, $v_right;
push @temp_changes, $change_left;
push @temp_changes, [$level + 1, 0], [0, $level + 1];
push @temp_changes, $change_right;
}while(@next && !$graph->has_vertex($member));
@next = @temp_next;
@changes = @temp_changes;
redo if !$graph->has_vertex($member);
}
return $graph;
}
sub curious_fraction_tree{
my($member) = @_;
my $graph = initialize($member);
my($parent) = $graph->predecessors($member);
my($grandparent) = $graph->predecessors($parent);
return ($parent, $grandparent);
}
Matthew gets points for creativity and obvious, clear formatting with his cascading OR cases, and more points for a pop-culture reference to make my job more interesting.
So good on him for that. I like this one.
sub curious_fraction_parent{
my $a = int(shift());
my $b = int(shift());
if(
(($a == 1) && ($b == 1))
||
($a < 1)
||
($b < 1)
){
# This is the root node or an
# invalid node- there is no
# parent (only Zuul...)
return(undef, undef);
}
if($a < $b){
# We're a Left Node
return($a, $b - $a);
} else{
# We're a Right Node
return($a - $b, $b);
}
}
additional languages: Test_data, Raku
blog writeup: TWC 146: 10K Prime and CW Trees
When figuring out my own solution to the challenge, I looked at the tree and surmised that there must be some relationship between the nodes to derive the pattern, so I set about figuring out what that would be. This was succesful in short order (I wrote a blow-by-blow as I figured it out), but once I had it, this got me thinking about why someone would make such a construction and what properties it would have. I started modifying my script, as I sometimes do, to explore the data and see what came up, working various fractions upwards to their degenerate root.
As it had sparked my own curiosity, the tree had certainly lived up to its name. I didn’t, however have time to go very far with it. I had solved the task, or by the time I was done with it solved my own idea of what the task should be, and eventually moved on. But the questions remained, and I was hoping someone else might have the time and inclination to shed some light on the matter. It is, after all, a very curious fraction tree. Inquiring minds want to know.
Bruce Gray, I’m very pleased to report, has stepped in to provide the detail I could only touch on.
And I’m not even going to attempt to summarize it here. Interested parties should go immediately to his writeup — an extensive collection of notes he has gathered — on the subject of the Calkin–Wilf tree. Down the rabbit hole he maps out there are some very, very cool graphical depictions, some unexpected relationships, notes on drum patterns and a solid Blues Brothers quote.
I played around with various fractions. Bruce went and wrote some 200 test cases. My hat is off. He wrote utility routines to generate the test data, and extra routines to navigate the trees in unexpected ways.
To solve the task he presents two solutions. One provides the switch pattern we have seen before, with a twist on the reversal that highlights the symmetry in the construction:
sub Calkin_Wilf_tree_parent ( $aref ) {
die if @{$aref} != 2;
my ( $numer, $denom ) = @{$aref};
my $diff = $numer - $denom;
return $diff > 0 ? [ $diff , $denom ]
: [ $numer , -$diff ];
}
In a second submission, Bruce has hunted down a module called Math::PlanePath::RationalsTree, which will construct a Calkin-Wilf tree to work on and navigate:
use Math::PlanePath::RationalsTree;
use constant CW => Math::PlanePath::RationalsTree->new( tree_type => 'CW' );
# Note: Due to the use of `n` in the ::RationalsTree module (position vs navigation),
# this version of the code is only reliable below level 64 of the tree on 64-bit Perl.
# On my machine, this code fails 36 of the 202 tests.
sub task2 ( $s ) {
$s =~ m{ \A (\d+) / (\d+) \z }msx
or die;
my $parent = CW->tree_n_parent( CW->xy_to_n($1, $2) );
my $grand = CW->tree_n_parent( $parent );
return map { join "/", CW->n_to_xy($_) } $parent, $grand;
}
As noted his version seems to work better.
Blogs and Additional Submissions in Guest Languages for Task 2:
additional languages: Raku
additional languages: Raku
additional languages: Raku
blog writeup: PWC146 - Curious Fraction Tree - ETOOBUSY
additional languages: Javascript, Ruby
additional languages: Raku
blog writeup: Perl Weekly Challenge: Week 146
blog writeup: Perl Weekly Challenge #146
additional languages: Awk, C, Julia, Kotlin, Lua, Python, Raku, Ring, Ruby, Scala
blog writeup: Perl Weekly Challenge 146: Prime Numbers and Fraction Tree
additional languages: Javascript, Kotlin, Lua, Postscript, Python, Raku, Ruby, Rust
blog writeup: RogerBW’s Blog: The Weekly Challenge 146: Curious Prime
additional languages: C++, Haskell, Raku
blog writeup: Perl Weekly Challenge 146 – W. Luis Mochán
BLOGS
That’s it for me this week, people! Warped by the rain, driven by the snow, resolute and unbroken by the torrential influx, by some miracle I somehow continue to maintain my bearings.
Looking forward to next wave, the perfect wave, I am: your humble servant.
But if Your Unquenchable THIRST for KNOWLEDGE is not SLAKED,
then RUN (dont walk!) to the WATERING HOLE
and FOLLOW these BLOG LINKS:
( …don’t think, trust your training, you’re in the zone, just do it … )
Abigail
- Perl Weekly Challenge 146: 10001st Prime Number ( Perl )
- Perl Weekly Challenge 146: Curious Fraction Tree ( Perl )
Adam Russell
Arne Sommer
- Fractionally Prime with Raku and Perl ( Perl & Raku )
Bruce Gray
- TWC 146: 10K Prime and CW Trees ( Perl & Raku )
Dave Jacoby
Flavio Poletti
- PWC146 - 10001st Prime Number - ETOOBUSY ( Perl & Raku )
- PWC146 - Curious Fraction Tree - ETOOBUSY ( Perl & Raku )
Jaldhar H. Vyas
- Perl Weekly Challenge: Week 146 ( Perl & Raku )
James Smith
- Perl Weekly Challenge #146 ( Perl )
Laurent Rosenfeld
Luca Ferrari
- Perl Weekly Challenge 146: the first challenge of the year! – Luca Ferrari – Open Source advocate, human being ( Raku )
- Perl Weekly Challenge 146: the first challenge of the year! – Luca Ferrari – Open Source advocate, human being ( PostgreSQL )
Mark Senn
- 10001st Prime Number ( Raku )
- Curious Fraction Tree ( Raku )
Peter Campbell Smith
- Large primes and curious fractions ( Perl )
Roger Bell_West
- RogerBW’s Blog: The Weekly Challenge 146: Curious Prime ( Perl & Raku )
Simon Green
- 2 Fractions and a Prime ( Perl )
W. Luis Mochan